
> How are you today?
* I’m afraid AI will change the legal profession.
> How long have you been afraid AI will change the legal profession?
* Since I started speaking to AI researchers.
> Can you elaborate on that?
* They were telling me about their latest research.
> I don’t understand you.
* Neither did they, that’s why I wanted to see a therapist.
> Tell me more…
The above conversation shows one of the first AI programmes, Joseph Weizenbaum’s 1966 ELIZA, in action. ELIZA, an intentionally condescending approximation of Rogerian psychotherapy, didn’t try to understand language at all, it merely reordered the user’s statements as questions and gave random prompts. Today it would be classed as a chat-bot rather than an AI system. In spite of its simplicity, some people were fooled into thinking they were having a conversation with a human therapist. Arguably, ELIZA passed a low-bar Turing test, the AI benchmark proposed by pioneering computer scientist Alan Turing of a machine able to exhibit intelligent behaviour that a human cannot distinguish from another human. As with so many early AI programmes, ELIZA turned out to be a false dawn. Continued research gave us better chat-bots, not HAL 9000. But, nearly 50 years later, AI researchers are again confident that their field is about to transform the world.
 According to Ray Kurzweil, director of engineering at Google, we’ve got until 2029. That’s the date Kurzweil predicts human intelligence will be matched, and swiftly surpassed, by machines. A more modest and frequently repeated prediction from tech research group Gartner is that by 2025 around one third of current jobs will be largely automated.
According to Ray Kurzweil, director of engineering at Google, we’ve got until 2029. That’s the date Kurzweil predicts human intelligence will be matched, and swiftly surpassed, by machines. A more modest and frequently repeated prediction from tech research group Gartner is that by 2025 around one third of current jobs will be largely automated.
Fascination and anxiety over sophisticated machines replacing workers is nothing new. In 1933 John Maynard Keynes made the oft-cited forecast of mass unemployment ‘due to our discovery of means of economising the use of labour outrunning the pace at which we can find new uses for labour’. However, recent advances in information technology and internet-backed services, the ubiquity of powerful portable computers in smart phones and tablets and the emergence of technologies like self-driving cars have given the debate an entirely new potency.
Lawyers may breathe a sigh of relief and pity the manual labourers facing unemployment, but the predictions are that the next machine revolution will cut high up into the professional hierarchy, turning many white-collar professions on their head.
A number of economists have put forward the idea that automation is hollowing out middle-income jobs once thought safe, leaving a polarised workforce of the low-skilled at one end and the highly educated, highly paid knowledge workers at the other. Proponents of this view, particularly those with a gloomy mindset, note how few workers are employed by tech titans such as Facebook and Google, compared to the traditional corporate giants of the 20th century. For example, Uber employed between 550 and 1,500 people last year, excluding drivers, and is now valued at around $50bn. US retailer Target Corporation, with a market cap of $47bn, employs nearly 350,000.
The reason why many believe that the law in particular will be transformed by AI and at least advanced automation is easy to grasp. Law and legal services are based on familiarity with codified information accessed and delivered through a very expensive professional framework relying heavily on one-to-one consultation. A much quoted 2013 report from two Oxford University researchers, which argued that 47% of jobs in the US were at high risk of being replaced by intelligent machines ‘in the next decade or two’, concluded that paralegals and legal assistants were in the high-risk camp. (The authors, Dr Carl Benedikt Frey and Michael Osborne, did, however, conclude that lawyers themselves were in the low-risk group, in an analysis that placed 702 jobs into high, medium and low risk from ‘computerisation’.)
The many advocates of automation foresee a world in which legal matters are primarily dealt with by machines, slashing the cost of legal services while turning the conventional law firm model on its head.
The legal technologist Richard Susskind – in his latest book, The Future of the Professions, written with his economist son Daniel – is one of many forecasting an industry in which ‘our professions will be dismantled’ in favour of ‘increasingly capable systems’.
These sentiments extend well beyond the small but growing band of legal futurists, with many major law firms sizing up the prospects of AI to transform the legal services industry.
But avoiding the hype and distortion in a hugely complex subject is a challenge. Predictions in this field have often proved widely off the mark, both over and under-estimating the impact of technology dramatically. As such, we have teamed up with Riverview Law for a special report on the prospects of AI in the law. Is AI, and, more broadly, advanced automation, about to transform the legal market? Will we see systems that not only automate work according to a predefined task, but that learn and improve as they go along? And will this really lead to the sea-change in the legal profession that many are predicting?
The surprisingly long history of AI and the law
Just as the genealogy of AI as a professional discipline is generally traced back to the 1956 Dartmouth conference in the US, AI and law can be said to have begun in earnest with the first International Conference on AI and Law, which took place in Boston in 1987. From that moment, a scholarly community of computer scientists and lawyers galvanised around the idea of bringing machine intelligence to the law. Trevor Bench-Capon, honorary visiting professor at the University of Liverpool’s Department of Computer Science, was one of the founding members of this community and editor of its journal. ‘In the 30 years that I’ve been involved in it, a lot of things have happened. Computers are a lot more powerful, and information that was only available on paper, such as case law, is now available online. Most important of all, lawyers who had never touched a keyboard when I started are now using technology at work all the time. In spite of all these changes, the main ideas we started out with in the 1980s are still the most important ones that guide the field. We’re still trying to represent legal arguments computationally and we’re still working on better ways of retrieving information. There’s been huge progress in computing, but the field itself still investigates most of the same issues.’
Many of the ideas in AI and law can be traced back to Lee Loevinger’s 1949 paper, ‘Jurimetrics: The Next Step Forward’, in which the use of mathematical techniques is suggested as a means of removing the determination of legal cases from the hands of lawyers, ‘a secret cult of a group of priestly professionals’. The legal AI movement started with a simple idea. The law is a system of rules and logic-based programming is very good at dealing with rules. The next step is to take a statute book and translate it into computer code. One of the earliest attempts to represent legal expertise in this was carried out by the Logic Programming Group at Imperial College. This project sought to codify the British Nationality Act (BNA) of 1981. The idea was to produce a programme that could check the residency entitlement of an applicant by taking some key information (date of birth, place of birth and so on) and having the system calculate the outcome of the case. The BNA System was deemed a success, but the relatively unambiguous nature of the information it relied on made it a poor test-case for systems modelling large and complex statutes. Subsequent research has led to much more advanced codifications of law, but the essential ideas behind the BNA System remain unchanged.
Computer scientists working on legal problems have tended to form two distinct and relatively unconnected groups. Crudely, one group has attempted to build systems that can understand human language and semantics while the other has applied machine learning and probability theory to large datasets. While there have been major advances in both fields, researchers believe the big breakthrough in automated legal analysis will come when ways are found of connecting these two branches of legal AI.
Bart Verheij, researcher at the University of Groningen’s Institute for Artificial Intelligence and Cognitive Engineering, comments: ‘On one side you have knowledge technology, which deals typically with logic based and associated with semantic web expert systems, business rules, open data and so on. They have applications in the law, but a problem for those kind of approaches is they are typically not so adaptive and not so strongly connected to data streams. On the other hand you have data technology. That side of things has strong connections to data streams but it is not so easy to have complex structures inside the data. What you would like to see is some kind of fundamental connection between the two. In the law it is exactly what is needed, because there is a role for both knowledge and data.’ Verheij’s own research explores the role of argumentation (the study of how conclusions can be reached through logical reasoning) in this process. ‘Argumentation shows how knowledge is connected to data. In a legal argument you look at facts, you find structures in facts, you present them as hypotheses and you test them. That kind of argumentation process is exactly what is needed in AI: to connect the knowledge technology side where complex structures are studied and processed and the data management side where we have all these files filled with natural language information.’
A question of semantic analysis
Given that senior lawyers have little interest in technology, the ripple of curiosity and concern about AI among law firms is striking. Many firms attended last May’s IBM World of Watson trade show and, as the recent flurry of press releases indicates, many more are trying to commercialise developments in the field of AI. The feeling that AI might be about to deliver on its promises is not just based on hype. There have been huge advances in the ecosystems that support intelligent systems technologies. The cost of memory, the speed of processing, increased connectivity of devices, and the capabilities of software have all improved dramatically in recent years. This has not so much led to a take-off in new technology as it has allowed existing technology to be applied in a cost-effective manner. At the same time, there have been incremental but important advances in AI and related fields of machine learning.
 ‘My take is that new technology is finally making inroads and connecting some of the computational logic researchers have been developing for the last few decades with sophisticated language processing tools,’ says Kevin Ashley, Professor of Law at the University of Pittsburgh and one of the world’s leading researchers in the field of computer modelling of legal reasoning.
‘My take is that new technology is finally making inroads and connecting some of the computational logic researchers have been developing for the last few decades with sophisticated language processing tools,’ says Kevin Ashley, Professor of Law at the University of Pittsburgh and one of the world’s leading researchers in the field of computer modelling of legal reasoning.
Dr Katie Atkinson, Professor of Computer Science and researcher at the University of Liverpool’s agent applications, research and technology group, is confident that AI-based systems will soon be a noticeable feature of the legal market. ‘We are starting to see people from start-ups and law firms present products at academic conferences. There were lots of promises that were made in the past about AI that have not been lived up to, but you will see products coming to the market in the coming months that draw on this research.’ Atkinson, whose research team at the University of Liverpool recently entered into a knowledge-transfer partnership with Riverview Law, is drawing on her work in data-mining, natural language processing and computational argumentation to help bring intelligent systems to the legal market.
Still, it is important to be clear on the terms of debate. Researchers often draw the distinction between ‘hard’ and ‘soft’ AI. While research into hard AI seeks to replicate the flexible and adaptive reasoning processes of the human brain, soft AI simply seeks to replicate human outputs in a narrowly defined task. Currently all working forms of AI are soft. The debate rages about when, if ever, there will be a breakthrough in hard AI; estimates from those working in the field vary widely from ‘several years’ to ‘never’.
In spite of advances in AI research, computer systems are still unable to act in anything resembling a cognitively-demanding context. ‘Advanced architecture allows for unstructured information management systems that can identify the way in which concepts or information are being used in legal cases, and machine learning can identify cases a human hasn’t tagged before, so it can identify sentences that state rules, extract and flag them,’ says Ashley. ‘That’s a big advance. Systems can incorporate rules into their logic without having them programmed in by a user. But they can’t explain their answers. That’s the bit we’re still missing.’
Bart Verheij, researcher at the University of Groningen’s Institute for Artificial Intelligence and Cognitive Engineering, has a similar take. ‘One of the main reasons we have not seen the huge progress in AI that we were dreaming of is that machines don’t understand what we’re doing as people. We tell machines a lot about our lives through social media, but they don’t understand our lives. A key element of the law is understanding what is going on. We are not near to achieving that kind of understanding in machines.’
While many are confident that their work will be brought to market within the coming months, researchers are keen to emphasise that we are a long way from seeing ‘strong’ AI systems capable of replicating human thought. As Dr Roland Vogl, director of the Center for Legal Informatics (CodeX) at Stanford University, cautions: ‘There is some fantastic research in AI and law, but most of this is not what’s being offered to firms right now. People speak of theoretical developments in AI and then jump to the rise of new technology in law firms and conclude that the really cutting-edge AI stuff is changing the legal market, but that’s not the case. Law firms might be talking about disruptors and trying to reposition themselves, but most of the computer science behind these systems is not new at all.’
 Verheij also feels the relationship between academic research and commercial application is often overstated. ‘Even though we have made a lot of progress there is still no real breakthrough that we could call true artificial intelligence. Some of the successes people are talking about are technically at a very shallow level and the business side of AI is often not so very exciting for researchers, but these systems indicate what is possible.’
Verheij also feels the relationship between academic research and commercial application is often overstated. ‘Even though we have made a lot of progress there is still no real breakthrough that we could call true artificial intelligence. Some of the successes people are talking about are technically at a very shallow level and the business side of AI is often not so very exciting for researchers, but these systems indicate what is possible.’
At least part of the problem stems from the term AI itself which, as Burkhard Schafer, Professor of Computational Legal Theory at the University of Edinburgh, says, has misled many. ‘People do very good work in AI and law but it is not what the man in the street is hoping for when he thinks of AI. The term “intelligence” is being used here in the sense in which it is used in the Central Intelligence Agency. It’s really research into expert systems or decision support systems applied to huge amounts of information. A second sense in which these systems are intelligent is that you orient them toward observations made about behaviour and try to replicate their reasoning processes. In idealised AI you are trying to replicate it to such a degree that a machine becomes indistinguishable from a human, but what AI researchers are really trying to do is generate similar outputs. We are simply asking which aspect of legal behaviour we can replicate sufficiently well to relieve lawyers of some of the burden of their job.’
Schafer makes a key point. In many regards the compelling notion of AI blinds and confuses the general observer. But technological advances in law are likely to come from the productisation or systemisation of legal services. This is a process that will be underpinned by machine learning, data analysis and sophisticated algorithms, but the application of existing technology and a change of mind-set in how to deliver professional services will be just as important.
From this perspective, the most successful systems in legal technology are not adding intelligence but eliminating stupidity. They are identifying the parts of a process that can be automated without appreciable loss in quality and taking it away from highly paid workers.
Machine-learning technologies will play an important role in delivering these services, but technologically less-sophisticated systems will be just as important.
The Lawntrepreneurs
All of the above strongly suggests the real impact of automation in law will come with the application of well-established and cheap technology.
One of the simplest and most successful examples of a working system in computational law is TurboTax, used by millions of Americans each year to prepare their tax returns. In essence, TurboTax is a form of automated legal analysis that takes facts about individual circumstances and the tax code to produce an output (a completed tax return). The widespread adoption of this system stems from its simplicity. It works because it is applied to a single, well-defined problem. A range of similar domain-specific systems are now being developed for the in-house and law firm market, most requiring little or no technological expertise to operate.
‘What we are excited about at CodeX,’ says Vogl, ‘is that the internet and widespread availability of legal data lets us make progress without needing the most advanced systems. This is where there is a real change coming, and it’s coming from the bottom up. It’s still relatively new to have start-ups in the legal industry, but it is happening now. That’s why I think it’s not a matter of if but when the market changes.’
The relative lack of technological sophistication at law firms and the domain-specific nature of a lot of legal work has led to a highly fragmented market for legal tech. It is striking that many of the legal tech start-ups are coming out of university departments, the so-called Homebrew Computer Clubs of law. As Ken Grady, the chief executive of SeyfarthLean Consulting, who teaches at Michigan State University’s ‘LegalRnD’ programme, notes: ‘We are seeing a significant number of entrants come in and try to devise new tech solutions for the industry. It’s the first time it’s happened really. Young, ambitious students are no longer just looking at how they can get into a top-tier firm, they are exploring how they can transform the legal industry with technology.’
Catering to this ambition, a number of universities are offering courses in legal technology and incorporating more software into their programmes. For example, students at Georgetown University use software provided by Neota Logic to build and test legal delivery apps as part of the university’s acclaimed Iron Tech Lawyer competition. Neota Logic, a no-code delivery platform that can be configured to deliver substantive legal advice by those with no background in programming, now offers its software free to a number of universities in the US and Australia.
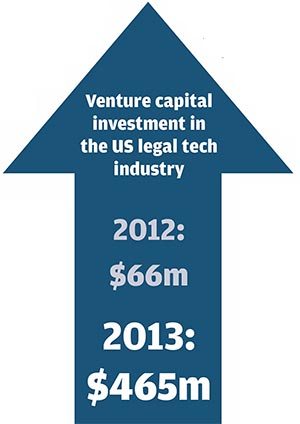
Investors, too, seem to believe we are heading for a tech-led shift in the legal market. Total venture capital investment in the US legal tech industry rose from around $66m in 2012 to around $465m in 2013, according to figures from CrunchBase, a database of tech start-ups run by online publisher TechCrunch. LegalZoom, Rocket Lawyer and Axiom were the top three beneficiaries, between them raising over $250m that year. Though reliable statistics are hard to come by, the figure is estimated at over $400m for 2014. While the venture capital market is notoriously volatile and offers little indication of long-term trends, it does suggest that investors now see potential for disruption.
Further evidence of a sea-change in the industry can be seen in the many trade shows that cater to the legal technology market. The list of exhibitors at the bi-annual LegalTech Conference, held in New York and San Francisco, gives a sense of the range of companies entering the sector. And it is big business. According to Professor Oliver Goodenough, director of the Centre for Legal Innovation at Vermont Law School, the legal tech industry is now worth up to $30bn (around 10% of the annual value of the US legal industry). While the legal tech market has traditionally been dominated by e-discovery providers or suppliers of software to large firms, tradeshows are increasingly attended by companies that are looking to offer services directly to clients.
Karl Chapman, chief executive of Riverview Law, notes a general shift in the way both start-up companies and investors are thinking about the legal services industry. ‘I spend a lot of time looking at the new tech ventures in the US and it’s really staggering. The tech companies out there are no longer saying, “How do we make law firms more efficient?”, they’re saying, “How do we disintermediate?” That’s why we shifted from being a technology-enabled company to a technology-led company. We became determined that if anyone is going to disintermediate us it will be ourselves.’
If technology must be part of the solution to an inefficient legal industry, tech sceptics point out that it is also part of the problem. The volume of electronically-stored information has grown exponentially in the last decade and while tech-driven tools are lowering costs of processing data per terabyte, they are not lowering costs overall. The explosion of data and technical and organisational complexity means in spite of improvements, technology is running to stand still in many contexts. Dramatic advances in technology have made the law much more efficient, but have not so far resulted in a reduction in the number of legal professionals.
By enabling more data review to take place in a shorter time and at a lower price, technology encourages more data to be presented for review. Put simply, this is Parkinson’s law of data applied to the legal profession: ‘Data expands to fill the space available for storage.’ The explosion of data and cases means that traditional legal research systems are struggling to cope. The typical large organisation now has tens, if not hundreds of thousands of contracts and agreements, and systems that allow lawyers to process this information are in demand.
Many of the new entrants to the legal tech market operate in the field of contract management, applying sophisticated algorithms to large unstructured databases. For example, Kira Diligence Engine offers a contract analysis tool that can explore a data room and extract information for diligence review. Legal OnRamp, which partnered with Riverview Law last year, uses aspects of IBM’s Watson to identify and process thousands of contracts to help institutions better manage their risk.
Dutch contract management software provider Effacts was recently acquired by Wolters Kluwer. The publisher has also acquired ELM (formerly TyMetrix), which along with CEB produces the Real Rate Report identifying the actual cost of legal services by provider, rather than their reported rates, along with spending trends. Large publishers of legal information must now be considering whether they continue selling to law firms or risk their primary revenue stream by trying to disintermediate. It would be a bold move, but with improvements in data management and legal analytics it is no longer an inconceivable one. At the same time, legal publishers are now facing their own disintermediation risk from venture-backed start-ups. Lex Machina, which began as a research project at Stanford’s CodeX, combines data mining techniques with advanced algorithms to search the entire archive of US IP litigation cases and predict a series of likely outcomes, from whether a judge is likely to dismiss a case to the strategy opposing counsel is likely to adopt. Ravel Law, a legal search, visualisation and analytics platform which raised over $8m of funding last year, grew out of two Stanford law graduates’ collaboration with the engineering faculty at the university. Other promising new entrants to the market include Modria, an online dispute resolution platform based on technology spun-out of eBay.
While it may be some time before research into the notoriously hard problems of AI such as automated legal reasoning are fully incorporated into practical systems, the ‘weak’ or ‘soft’ AI incorporated in these and many more start-ups’ offerings is thought by many to be the most likely means of producing a seismic shift in the legal market, realistically within the next five to ten years.
 The main limiting factor here is not technology, but the willingness of clients to engage with new ways of resourcing legal work. History suggests this will be a slow process. As Mike Mills, co-founder of Neota Logic, points out: ‘In-house teams are typically reluctant to use technology and the demonstration of that, at least in the US, is e-discovery. For years now there have been some very good tools based on advanced machine learning concepts that do a faster, cheaper and more accurate job than humans do in analysing large volumes of electronic data, but general counsel are not insisting that their law firms use it. It surprises me that general counsel do not have a universal rule that says “we will not pay attorneys to do discovery”.’ (See ‘The i-Team’).
The main limiting factor here is not technology, but the willingness of clients to engage with new ways of resourcing legal work. History suggests this will be a slow process. As Mike Mills, co-founder of Neota Logic, points out: ‘In-house teams are typically reluctant to use technology and the demonstration of that, at least in the US, is e-discovery. For years now there have been some very good tools based on advanced machine learning concepts that do a faster, cheaper and more accurate job than humans do in analysing large volumes of electronic data, but general counsel are not insisting that their law firms use it. It surprises me that general counsel do not have a universal rule that says “we will not pay attorneys to do discovery”.’ (See ‘The i-Team’).
Seyfarth’s Ken Grady sees something similar in the slow uptake of diligence review software. ‘Software like Kira Diligence Engine works. It can do things that would take a team of paralegals and attorneys many days to do, but you’re still not seeing everyone jump in and use it. You can show all sorts of charts and statistics but people are still going to be sceptical and ask whether it is catching the right type of information.’
While scepticism is essential when it comes to artificially intelligent legal systems, many of which will require a lot of road-testing before they are commercially viable, the fact that a technology-based approach is not perfect often misses the point. As legal tech specialist Ron Friedmann of Fireman & Company points out: ‘If your next best alternative is a room full of lawyers who are very expensive and whose error rates are well known to be far higher than the error rates of most software systems, then you can’t just dismiss technology as imperfect. Your valuation metric has to be set up properly; it can’t have perfect tech on one side and the status quo on the other.’
What is Watson?
It may not rank among the top 500 most powerful computers, but IBM’s Watson is undoubtedly the most famous supercomputer in the world. It is also the system most lawyers and legal futurists point to when discussing the potential for AI to transform the profession. There are good reasons for this interest. Ever since Watson in 2011 beat the two most successful players in the history of Jeopardy! at their own game anyone with a passing interest in the development of AI has been monitoring its progress, and any system capable of processing a million books’ worth of information per second is likely to catch the eye of those working with large amounts of complex information. But few people seem to be able to come up with the answer in response to Merv Griffin’s question: ‘What is Watson?’
At its heart, Watson is a system for hosting and processing large unstructured databases. The core of Watson’s power comes from the roughly six million logic processing rules that help it perform simultaneous data mining and complex analytics on the information stored within its servers, enabling it to extract data points far more accurately than previous systems. The prospect of a system capable of processing large amounts of unstructured data is a tantalising one for most corporations. According to a study conducted by the International Data Corporation (IDC) in 2012, only around 0.5% of available global data is used for analysis and 80% of all data is unstructured; a figure that has certainly risen since that time with the continued proliferation of social media and mobile communications. Unsurprisingly, IBM is putting a lot of effort into developing Watson for commercial application: the New York-based IBM Watson Group has 2,000 employees and is funded with $1bn in capital.
A second aspect of the system is that it can respond to requests for information without relying on keywords, enabling users to summarise a concept as they would do in normal speech. For example, provided the structure of the question is sufficiently clear, a request for information relating to the presence of indemnities in a contract will be processed by Watson even if the term ‘indemnity’ is not used. Further, Watson will not simply list the documents on its server containing a discussion of indemnities; it will isolate the relevant passages and suggest an answer to the question.
The final strand to this technology is its much-publicised machine learning component. While the initial calibration of Watson’s rule to a particular domain requires a lot of behind the scenes programming, automated learning capabilities – part of the AI that Watson is famous for – allows it to incorporate feedback from users to improve these rules automatically (ie without a programmer’s intervention). In this space, at least, Watson has some notable competitors, including Microsoft’s predictive analytics platform, Azure, and, more recently, Amazon Machine Learning. All of which highlights the fact that Watson is not really a single thing, but a family of related services drawing on the same underlying algorithms and data processing capabilities. When companies speak of ‘using Watson’ they are not purchasing a physical system but adopting certain members of the Watson family, via cloud computing, and integrating them with their own IT systems.
One of the most important aspects of Watson is its adaptability. It is worth remembering that, for all the attention Watson garnered for its ability to beat humans at a popular quiz, the system was not designed to play Jeopardy! in the same way that a programme like Deep Blue was written to play chess. Because the various tools of the Watson family can be adapted to so many different domains the scope for application is wide, but like any ambitious family IBM plans to send its children into medicine, law, and education.
The first commercial agreement seeking to bring Watson to market was signed between IBM and US healthcare insurer WellPoint (now Anthem) in 2011. This has since been expanded to include the Memorial Sloan Kettering Cancer Center in New York. By using Watson’s unstructured data processing capabilities to review a database of patient records, clinical notes, and thousands of test cases, the partnership should benefit patients, doctors and insurers by significantly reducing the time taken to pre-approve various therapies. Applying Watson to the legal industry is an intriguing and potentially lucrative idea, but one that may struggle to achieve the same economies of scale: not only is the data of medicine easier to handle – most scientific literature written in English and case notes tend to be recorded in a more or less standardised form – but the body is not subject to jurisdictional variation in the same way that a legal concept is. Nonetheless, many law firms and third-party suppliers are now taking Watson seriously enough to invest in their own systems (see ROSS Intelligence).
While optimism abounds, there are also a considerable number of sceptical voices. One senior IT lawyer who had spent time investigating Watson said he had trouble distinguishing its functionalities from Google and described it as ‘a very, very good search engine’ that may one day have general purpose AI layered on top. So, the big question, will Watson replace lawyers anytime soon? For now, at least, the answer is… probably not. According to Clyde & Co’s global IT director, Chris White, Watson is a ‘great discussion point’ that has encouraged people to think about how technology may be applied to the legal industry, but it will not change the profession in the short-to-medium term.
The real cutting edge
The intuition that legal documents ought to be particularly suitable for computational analysis has guided AI and law researchers for a long time, but, as Verheij says, it has not led to the expected results. ‘Legal decisions are typically all about details and the nuance of the specific words that are used, which is why the law is so interesting from a research perspective, but also why it’s so hard.’ Legal documents may be dry, but they are also full of tacit assumption and subject to interpretation.
If computers struggle to comprehend legal language, what if humans instead wrote laws in a language that computers can understand? The computational representation of contracts is a project Harry Surden, Professor of Law at the University of Colorado and resident fellow at CodeX, has been engaged in for the majority of his career. ‘My take is that computers can’t do natural language processing at the level necessary to make useful legal assessments and probably won’t be able to do so anytime soon’, says Surden. ‘But you can translate at least some legal assertions and statements into computer code.’ One of the big advantages of this approach, according to Surden, is that it reduces the transaction costs associated with contracts. ‘Large numbers of commercial contracts are for repeat orders in a stable supply chain and there is simply no need to have a human involved in any stage of this process.’
 The Computable Contracts Initiative at Stanford is working on developing a universal Contract Definition Language (CDL) – a rules-based logic programming language designed for expressing contracts – that will allow terms and conditions to be represented in a machine-understandable way. An automated contracting system would, at least in principle, be able to check a contract’s validity with respect to the laws as well as calculate the utility of a contract for achieving certain aims.
The Computable Contracts Initiative at Stanford is working on developing a universal Contract Definition Language (CDL) – a rules-based logic programming language designed for expressing contracts – that will allow terms and conditions to be represented in a machine-understandable way. An automated contracting system would, at least in principle, be able to check a contract’s validity with respect to the laws as well as calculate the utility of a contract for achieving certain aims.
While there is a lot in a typical contract that cannot be represented particularly well in computable form, Surden points out that the real-world evidence of whether money was transferred or goods arrived at a location is already recorded by computers as financial or tracking data. As a result, companies could manage their contractual obligations much more efficiently with computable contracts than they could by applying even the most sophisticated analytic techniques to natural language contracts.
It is often claimed that there is something unique about legal obligations that requires human oversight, but Surden thinks this objection has been overstated. ‘If you speak to anyone in business then the most important things in a contract are the simple things. A typical contract may have 59 clauses, but 57 of them are irrelevant. They’re there to quantify risks in the event of a disaster. It’s those two key clauses you care about 99.9% of the time, and they can be monitored by a computer.’ Indeed, in finance automated and computer executed equity options contracts are already the norm. ‘These documents are not written in human language but as data records that few lawyers would be able to read. Disputes still arise if people accidentally enter into a financial contract when they intended to specify something else, but there are various provisions and internal processes for dealing with those disputes. The system is so well integrated with the practice of finance that people forget it represented a big change in the way financial contracts got written just a few years ago.’
A related, but still more distant prospect comes in the form of smart contracts. While computable contracts would only be used within an established supply chain or institutional trading network, smart contracts are designed for any type of commercial transaction. The term smart contract was first proposed by the cryptographer and legal scholar Nick Szabo in 1993, but serious attempts to create such a platform have only just begun. One notable development in this field is Ethereum, a programming platform that helps distribute smart contracts among users.
This, in Vogl’s opinion, is one of the most exciting areas of legal informatics. ‘Smart-contracts research really is applying computer science to contract law. Contracts that are operationalisable – ie where a computer can perform the contract – are a huge opportunity that people are trying to break into. This is something that is really exciting and at the cutting edge of our field. There is huge scope here for disruption in the market. This could be the way the corporation of the future operates.’
Data-oriented contracting is an area in which human willingness to reimagine ways of executing the law is at least as important as technological advances. According to Professor Michael Luck, Dean of Faculty of Natural and Mathematical Sciences at King’s College: ‘We are at the point in computing where we have systems that can do a lot of this already. They do transactions electronically and provide services in an automated fashion, but we haven’t used machines for doing more legal aspects of that work thus far. We are still not quite where we need to be in terms of application. It’s partly technological, but it’s mainly because people are not ready to turn such things over to machines. But there are a lot of automated provisions of electronic services that we take for granted. We just haven’t put the next layer above. We need the environment to catch up.’
Disrupted, this time
It is notable that academics and technologists working at the frontiers of computer science are often more pragmatic and less hyperbolic regarding the transformative impact of AI than others. For example, there is a good deal of cynicism in such circles about the industry hype built up regarding IBM’s Watson (see ‘What is Watson?’, opposite).
What looks most likely to impact on law in the foreseeable future is a change in mind-set and a growing demand that firms approach more legal problems via tech-backed systems rather than as a guild of high-status professionals.
In law, this looks to be the prime suspect to deliver the ‘disruptive innovation’ proposed by the academic Clayton Christensen, whereby new entrants up-end the business model of leading industry players. In the short-to-medium term, the most fertile ground for such disruption is the routine-heavy areas of law involving large groups of contracts and huge amounts of data, such as litigation discovery and compliance work.
More powerful forms of AI may be the fuel that dramatically accelerates this process, but the productisation of law is where the real progress is currently being made.
 There are already a group of providers, among them Riverview Law and Axiom, some legal process outsourcers and a handful of law firms using technology to remodel legal processes. A number of in-house teams are also taking an interest – though, unlike in Christensen’s model, it is currently large institutional buyers rather than marginal early adopters that are progressively experimenting with such tools.
There are already a group of providers, among them Riverview Law and Axiom, some legal process outsourcers and a handful of law firms using technology to remodel legal processes. A number of in-house teams are also taking an interest – though, unlike in Christensen’s model, it is currently large institutional buyers rather than marginal early adopters that are progressively experimenting with such tools.
Does this herald the end of professions and mass unemployment? In many regards the answer appears to be no, though the consensus among specialists in the area is that there will ultimately be proportionately fewer legal professionals required in 20 years’ time. Keynes’ analysis of the impact of technology on labour has, after all, proved wrong many times. And there will also likely be a host of new jobs, working on the interface between technological systems and the law. It seems likely there will soon come a day when major legal services providers will spend a lot more on technology than they currently do on rent.
In this regard some turn to the augmentation theory of automation – the idea that, as machines take on increasing parts of the workflow, humans will evolve towards areas in which they have comparative advantage against technology. This concept is expressed at the conclusion of the much cited Oxford report that, as technology races ahead, workers will ‘reallocate to tasks that are non-susceptible to computerisation – ie, tasks requiring creative and social intelligence’ before concluding: ‘For workers to win the race… they will have to acquire creative and social skills.’
In law, the cognitively and socially advanced skills of negotiation, business development, client handling and forming judgements in the face of poor information won’t be replaced anytime soon and, as such, will probably command a greater premium.
It should also be remembered that automation has to be not only possible, but commercially viable against the benchmark of a person. The Oxford report, for example, concludes that there will be relatively quick computerisation of many jobs before engineering and technology bottlenecks slow the advance of automation.
Likewise, the march of technology suggests that many services will become commercially viable thanks to the ability to process huge amounts of information. An example of this can be seen in accounting, where technology is leading a shift from auditing via sample to a ‘total audit’, where every transaction a company carries out could be included in the audit. In a legal context that could constitute real-time analysis of all a company’s contracts and legal exposures.
Such factors suggest that there will be a considerable period of evolution in which roles, skills and resources will re-allocate as technology impacts on law, though it is hard to dispute that the process will lead to profound change in the next ten years, let alone beyond that.
But the law will not merely be a passive partner. As Verheij concludes: ‘Many people think that technology will change the law, which is true and in fact happening, but also rather mundane. What is more interesting is that I expect that the needs of the law will lead to significant changes in technology.’
For the full report published by Legal Business please see: ‘AI and the law tools of tomorrow: A special report’